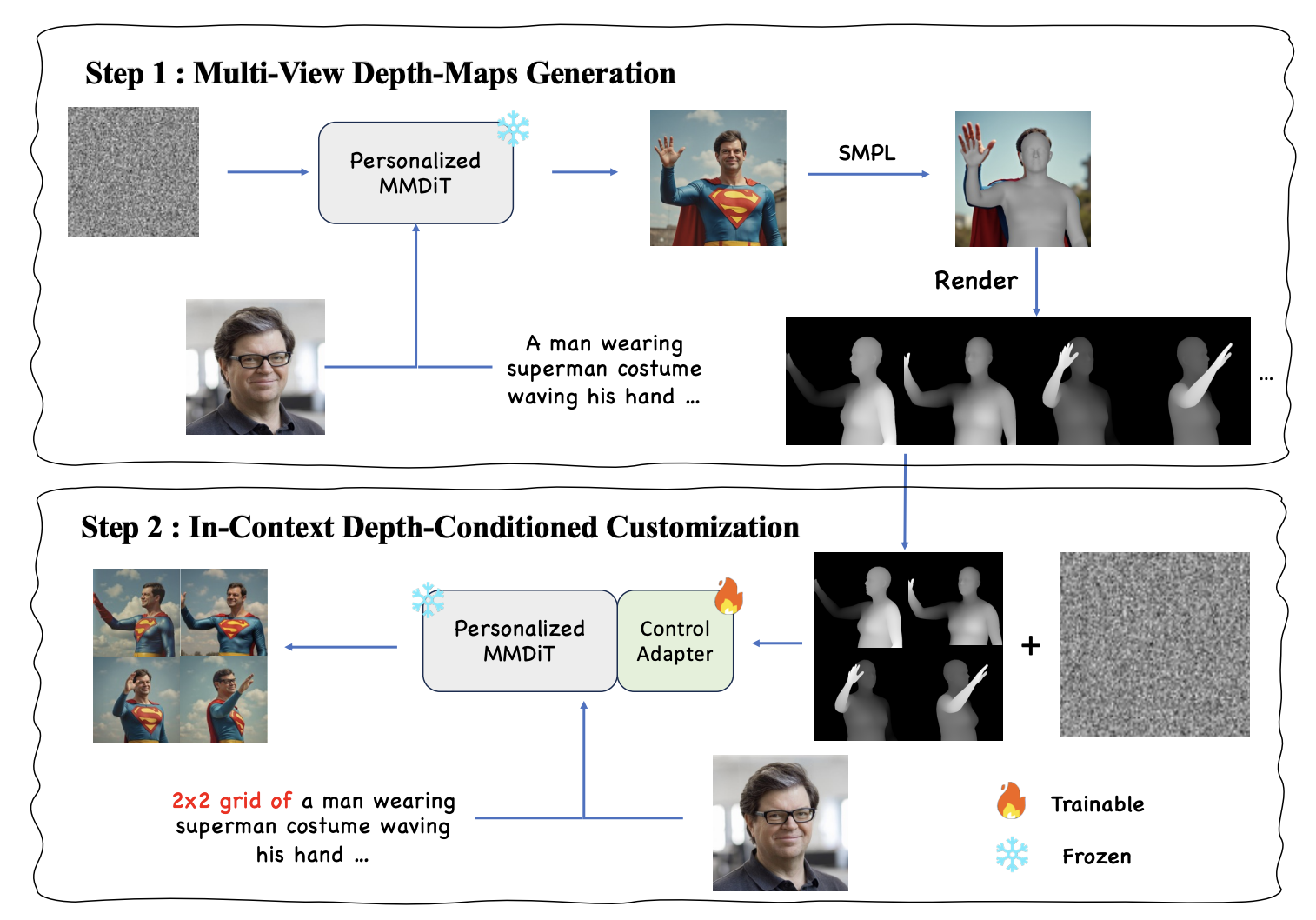
Recent advances in personalized generative models demonstrate impressive results in creating identity-consistent images of the same person under diverse settings. Yet, we note that most methods cannot control the viewpoint of the generated image, nor generate consistent multiple views of the person. To address this problem, we propose a lightweight adaptation method, PersonalView, capable of enabling an existing model to acquire multi-view generation capability with as few as 100 training samples. PersonalView consists of two key components: First, we design a conditioning architecture to take advantage of the in-context learning ability of the pre-trained diffusion transformer. Second, we preserve the original generative ability of the pretrained model with a new Semantic Correspondence Alignment Loss. We evaluate the multi-view consistency, text alignment, identity similarity, and visual quality of PersonalView and compare it to recent baselines with potential capability of multi-view customization. PersonalView significantly outperforms baselines trained on a large corpus of multi-view data with only 100 training samples.